Most AI output fails the first read aloud test. It sounds correct, technically. It does not sound like anything a specific person or brand would actually write. The fix is older than the modern AI boom but rarely taught well: stop describing the desired output and start demonstrating it. The technique has a name. Reverse-prompting.
| QUICK REFERENCE CARD | |
| Technique | Reverse-Prompting (also known as style cloning, example-led prompting) |
| Family | Few-shot prompting |
| Sample sweet spot | 3 to 5 examples |
| Best-performing models | Claude Opus 4.7, GPT-5.5, Gemini 2.5 Pro |
| Primary benefit | 40 to 60 percent reduction in editing time |
| Difficulty | Beginner to intermediate |
| Risk areas | Ideation tasks, factual research, weak source samples |
3-5 examples produce peak output quality | 50% average reduction in editing time | 2 modes: example-led and style extraction | 2026 the year reverse-prompting went mainstream |
Defining Reverse-Prompting
DEFINITION Reverse-prompting is the practice of feeding an AI model concrete examples of desired output and asking the model to produce more in the same shape, instead of describing the desired output in adjectives. The technique is a specific application of few-shot prompting. |
The Two Working Modes
Reverse-prompting operates in two modes that often combine inside the same workflow.
Mode A is example-led generation. Samples of writing, code, or design output are pasted into the prompt with an instruction to generate additional items in the same shape. The model infers tone, vocabulary, structure and rhythm from the samples and produces new items that match the pattern.
Mode B is style extraction. A successful output is pasted into the prompt with an instruction to reverse-engineer the underlying rules. The model returns a reusable system prompt that captures the structural decisions behind the original. That extracted prompt becomes a template for future work.
How the Technique Got Named
The phrase reverse-prompting moved from prompt engineering forums into mainstream practice between late 2024 and early 2026. Earlier names included example-led prompting, style-anchoring, and pattern prompting. The reverse label stuck because the workflow runs backward from the usual flow: instead of writing instructions and hoping the output matches, the practitioner starts with the desired output and works backward to a reproducible prompt.
The Core Principle: Show, Not Tell
Three properties of modern large language models explain why reverse-prompting works.
Pattern Matching
Language models trained on internet-scale corpora are exceptionally good at extracting structural patterns from short sequences. Two confident, punchy openings supplied as examples will produce a third in the same register without any further instruction.
In-Context Learning
When examples appear inside the prompt window, generation adapts to fit those examples without any change to the model's underlying weights. The adaptation is temporary, scoped to the conversation, and reversible by deleting the examples.
Specificity
A real piece of writing carries dozens of micro-decisions about word choice, paragraph break placement and sentence rhythm that would be tedious to describe in instructions. A single example transmits all of them at once.
The comparison below makes the contrast concrete.
| Aspect | Standard Prompting | Reverse-Prompting |
|---|---|---|
| Input type | Adjectives and instructions | Concrete artifacts plus instruction |
| Variance between runs | High | Low |
| Style fidelity | Approximate | High |
| Best for | One-off generic tasks | Repeatable on-brand work |
| Scales to teams | Hard, every writer guesses | Easy, templates are shared |
The Five-Step Production Workflow
The workflow most practitioners converge on has five distinct stages.
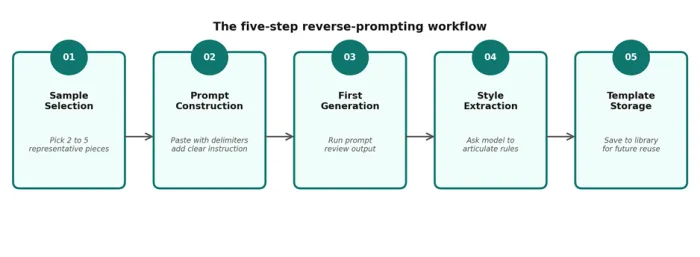
Figure 1. The five-step reverse-prompting workflow.
Stage 01: Sample Selection
Two to five pieces of work are chosen. Each one must be representative of the desired tone and structure. Diversity within the samples matters. Five near-identical examples teach the model less than three examples that span the natural variation in the target style.
Stage 02: Prompt Construction
Samples are pasted into the prompt with clear delimiters between them. A short instruction at the end specifies the task: produce one or three or ten new items in the same style.
Stage 03: First Generation
The model produces output. The output is evaluated against the original samples on three axes: tone, structure and voice match.
Stage 04: Style Extraction
If the output is close but imperfect, the model is asked to articulate the rules it inferred. The articulated rules become a reusable system prompt.
Stage 05: Template Storage
The system prompt is saved to a prompt library or workflow tool. Future requests in the same style call the saved template rather than re-pasting the original samples each time.
The Sample-Size Sweet Spot
Output quality rises sharply between zero and three examples and plateaus around five. The chart below summarises the relationship across benchmarks and practitioner reports.
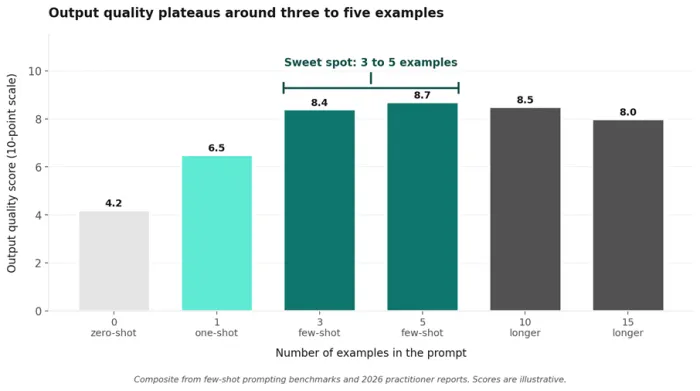
Figure 2. Three to five examples mark the practical sweet spot for most content types.
PRO TIP For very long samples, slightly fewer examples often outperform more examples. Attention dilutes across long context windows, so two 800-word samples can produce better output than five 400-word samples when the long-form structure matters more than micro-style. |
Templates by Content Type
Different content types call for different reverse-prompting structures. The table below summarises the templates that have emerged as standard practice across professional writing teams in 2026.
| Content Type | Samples Needed | Key Elements | Refresh Cadence |
|---|---|---|---|
| Blog posts | 3 to 4 paragraphs | Hook, flow, voice | Quarterly |
| Email sequences | 1 to 2 full chains | Subject, opener, CTA | Quarterly |
| Product descriptions | 4 to 5 short samples | Length, framing, closer | Twice yearly |
| LinkedIn posts | 3 strong examples | Hook, story, takeaway | Every 6 to 8 weeks |
| Code snippets | 2 well-commented files | Naming, errors, comments | Per project |
| Newsletter issues | 2 past editions | Sections, sign-off | Monthly |
Blog posts benefit from three full-paragraph samples covering intro, mid-section and conclusion structures. Email sequences work well with one or two example chains shown in full, with a clear request for a new chain on a different topic. Code samples typically need two well-commented snippets that establish naming conventions, error handling style and comment density.
Model-by-Model Performance Notes
Not every model handles reverse-prompts equally well. The comparison below reflects practitioner observations across major platforms as of May 2026.
| Model | Context Window | Style Match | Best For |
|---|---|---|---|
| Claude Opus 4.7 | 1M tokens | Excellent | Long-form prose |
| GPT-5.5 | 400K+ tokens | Excellent | Mixed format |
| Gemini 2.5 Pro | 2M tokens | Strong | Large libraries |
| Claude Haiku 4.5 | 200K tokens | Strong | High volume |
| Local open-source | Varies | Moderate | Privacy work |
Models with very large context windows excel at reverse-prompts that include several long samples. Models tuned for instruction following handle style extraction reliably. Open-source local models lag slightly on subtle voice matching but have closed much of the gap over the past 18 months.
Five Mistakes That Wreck Output Quality
Five mistakes account for the majority of reverse-prompting failures. The chart below ranks them by estimated impact on output quality.
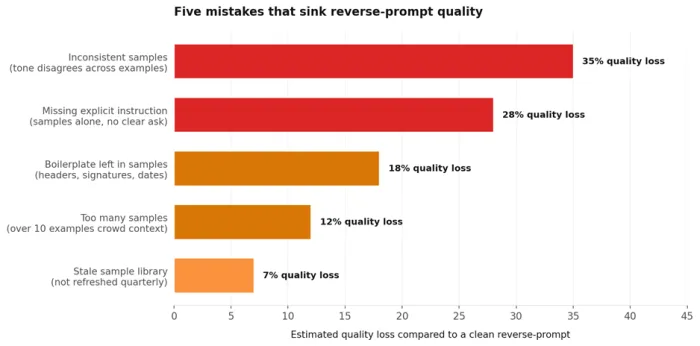
Figure 3. The five most common reverse-prompting mistakes, ranked by quality impact.
Inconsistent Samples
Three examples that disagree on tone leave the model to average them. The averaged voice sounds like none of the originals and creates output that reads as uncanny. Fix: pick samples that genuinely share the target voice, not just the target topic.
Missing Explicit Instruction
Samples alone leave the task ambiguous. A clear request after the samples anchors the generation. Fix: end with a one-line instruction such as write one new product description for the following product.
Boilerplate Left in Samples
Headers, footers, dates and signatures get treated as part of the pattern unless explicitly excluded. The output then includes phantom signatures or stale date stamps. Fix: trim samples to body text only.
Too Many Samples
Past ten examples, attention spreads thin and structure begins drifting. The output reads like a hybrid of every sample at once. Fix: stop adding examples once the third one matches the target style.
Stale Sample Library
Style drifts over months. A library refreshed quarterly produces better results than one frozen at launch. Fix: schedule a quarterly review of the active sample set.
When Reverse-Prompting Is the Wrong Choice
AVOID WHEN The desired output requires novelty (brainstorming, ideation), factual accuracy above style (research summaries, citation work), or when the available source samples are below the quality bar the new output should hit. Reverse-prompting amplifies the pattern in the samples, including any weaknesses they carry. |
Three categories deserve direct flagging.
Highly factual research where the priority is accurate information rather than style. Reverse-prompts can lock in the form of the original output, including any errors it contained. Style cloning is not fact cloning.
Creative ideation where novelty is the goal. Examples constrain the search space, which is the opposite of what brainstorming needs. For pure idea generation, zero-shot or open-ended prompting produces wider variation.
Tasks below the model's standard quality bar. Pattern matching on weak samples produces weak output. Garbage in, polished garbage out.
The 2026 Tool Stack
Three tiers of products now support reverse-prompting workflows.
Built-in Prompt Libraries
Claude, ChatGPT and Gemini all ship with prompt library features. Extracted system prompts can be saved and recalled across conversations without re-pasting samples each time.
Standalone Prompt Management
PromptHub, PromptLayer and LangSmith provide version control, A/B testing and team sharing for reverse-prompts at the enterprise level. These tools matter when more than one person is generating output against shared templates.
Specialised Research Models
Dedicated models for prompt reconstruction are starting to appear. DEJAN AI published work in March 2026 on a fine-tuned Gemma 3 270M model trained on 100,000 synthetic prompt-response pairs to reverse-engineer prompts from outputs. The signal is clear: prompt reconstruction is becoming a discipline of its own.
Measuring Success
Three metrics matter when evaluating whether a reverse-prompt is production-ready.
- Tone Match
Read the output aloud alongside the original samples. Tone mismatches surface within seconds. Score 1 to 5.
- Structure Match
Compare paragraph rhythm, sentence length distribution and section flow. Structural drift is often more visible than tone drift. Score 1 to 5.
- Edit Time
Time the cleanup from first draft to publishable output. A working reverse-prompt should cut edit time by 40 to 60 percent compared to a vague instruction. Score 1 to 5.
Averaging the three scores across ten generations gives a reliable signal for whether the template is ready for production or needs more sample diversity.
Common Misconceptions
Five myths that show up regularly in prompt engineering discussions.
MYTH Reverse-prompting is the same as few-shot prompting. | REALITY Reverse-prompting is one specific application of few-shot prompting, focused on style transfer and template extraction. Few-shot is the umbrella technique. Reverse-prompting names the production workflow. |
MYTH More examples always produce better output. | REALITY Output quality plateaus around five examples and starts to decline past ten. Attention dilution and context crowding make additional samples actively harmful in many cases. |
MYTH Reverse-prompting only works on expensive paid AI plans. | REALITY Most reverse-prompting techniques work on free tiers. Paid tiers offer longer context windows that help when samples are long, but the core technique is free to use. |
MYTH Reverse-prompting can clone any writer's voice perfectly. | REALITY Pattern fidelity is high but not absolute. Subtle voice elements such as humour timing, cultural references and emotional restraint remain hard to capture from short samples. |
MYTH Once a template is built, it never needs updating. | REALITY Style drifts over time. Best practice is to refresh sample libraries quarterly for most content types, monthly for newsletters and other voice-sensitive work. |
The Reverse-Prompting Cheat Sheet
Eight lines to bookmark and return to.
| Define | Show the AI the output instead of describing it |
| Pick samples | 3 to 5 pieces, representative, no boilerplate |
| Build prompt | Samples with clear delimiters, instruction at the end |
| Extract style | Ask the model to articulate the rules behind a great output |
| Store templates | Save extracted prompts to a library for reuse |
| Refresh | Update samples quarterly to prevent style drift |
| Measure | Score tone match, structure match, edit time on 1 to 5 scale |
| Skip when | Brainstorming, factual research, weak source samples |